La plupart des personnes travaillant dans une grande entreprise ou au sein d’une collectivité locale et qui y utilisent un ordinateur ont probablement déjà entendu parler de la notion de proxy. Le proxy est ce serveur incontournable pour leur permettre d’accéder à Internet, et qui permet aux entreprises à la fois d’optimiser la bande passante consommée (le volume de données) tout en mettant en place des filtres pour restreindre les contenus autorisés.
La notion de reverse proxy est en revanche étrangère à la majorité des utilisateurs classiques du réseau Internet car elle est plutôt familière des administrateurs ou des architectes système et réseaux, voire des équipes de développement.
Un reverse proxy, communément appelé serveur de cache ou encore proxy inverse, est pourtant un maillon fondamental dans la montée en charge des sites et applications Web à fort trafic, bien que transparent pour l’utilisateur final.
1. Introduction
Cependant, l’objectif est simple, à savoir soulager les serveurs d’applications chargés de générer les pages qui sont ensuite consommées par les navigateurs clients.
Comment procèdent-ils ? Pour aller à l’essentiel et avant de rentrer plus dans les détails, il faut retenir qu’un reverse proxy joue le rôle d’intermédiaire entre son propre navigateur et le serveur que l’on demande (derrière un site Web se cache en effet un ou plusieurs serveurs). Si le contenu interrogé ne contient pas d’élément spécifique à sa propre session utilisateur (des informations comme l’identité, le panier d’achats, des fonctions communautaires liées à son profil), le reverse proxy va stocker le contenu généré par le serveur et le servira directement au prochain utilisateur qui demandera la même ressource. Autrement dit, à la demande d’une page, le reverse proxy regarde s’il a cette page en cache, va la chercher s’il ne l’a pas et la stocke dans son cache avant de l’envoyer au poste client.
Ces serveurs sont extrêmement performants pour stocker des contenus et les resservir en l’état. Ils sont donc très importants en terme de gain de performance quand ils sont utilisés pour soulager des serveurs d’applications fortement sollicités. Les outils de gestion de contenu par exemple, comme Typo3, Drupal, WordPress et autres, sont assez consommateurs en ressources et en temps de génération de contenu, au point que nombre de ces outils intègrent des extensions permettant de faciliter leur combinaison avec un reverse proxy du marché.
Nous nous intéressons aujourd’hui à la solution libre et Open Source Varnish. Cet outil est publié sous licence FreeBSD (http://fr.wikipedia.org/wiki/Licence_BSD) par la branche Web d’un « Tabloïd » – n’ayant pas trouvé d’équivalent français en dehors de « presse à scandale » un peu trop connoté, on utilisera ce terme d’autant qu’une société publiant un outil tel que Varnish ne peut pas être foncièrement mauvaise 😉 – un « Tabloïd » donc, norvégien, nommé Verdens Gang (http://en.wikipedia.org/wiki/Verdens_Gang). Tout tabloïd qu’il soit, il se trouve être l’un des journaux les plus diffusés du pays, d’où l’importante problématique de montée en charge pour sa version Internet, qui a justifié l’élaboration de Varnish.
L’architecte et développeur principal de Varnish se nomme Poul-Henning Kamp, connu pour sa contribution au cœur du système d’exploitation UNIX FreeBSD.
Contrairement aux solutions concurrentes de reverse proxy comme Squid, NGinx, ou le module dédié de Apache, Varnish est le seul logiciel à avoir été purement conçu comme un proxy inversé : il n’a pas d’autre rôle quand les autres sont à la base des solutions de proxy classiques ou des serveurs Web.
2. Principes généraux
En matière de site Web, il existe, depuis pratiquement l’origine du média, deux grands types de contenus : les ressources statiques et les ressources dynamiques. Les ressources statiques sont les images, les fichiers audios, les pages HTML, les fichiers javascript, les feuilles de style CSS. Elles sont opposées aux ressources dynamiques par l’absence d’exécution d’un programme pour les obtenir, et sont restituées en tant que tel par le serveur Web. Les ressources dynamiques, elles, sont fabriquées par des programmes logiciels, soit des scripts CGI, soit des applications s’exécutant dans des conteneurs Web applicatifs tels que PHP, Tomcat, IIS/ASP.Net, Ruby, etc. Ces applications procèdent à un ensemble d’opérations pour généralement accéder à des ressources tierces (bases de données, annuaires, services Web, etc.) et/ou exécuter des algorithmes métier ou techniques.
Autant les serveurs Web classiques comme Apache HTTP Server et Microsoft IIS sont assez bons pour répondre dans des temps satisfaisants et faire face à une importante montée en charge pour servir des ressources statiques, autant le couplage à un conteneur Web pour construire des contenus dynamiques est plus sensible, et l’on peut rapidement se retrouver dans une situation où cette brique de l’architecture se transforme en goulet d’étranglement (soit le serveur d’applications lui-même, soit l’une des briques dont il dépend, comme le serveur de bases de données par exemple).
On comprend ainsi rapidement l’intérêt d’un proxy inverse. Celui-ci ne sollicitera qu’une fois le serveur d’applications pour de multiples requêtes utilisateur, et ce, le temps d’une durée de vie paramétrable de ce cache. L’intérêt est démultiplié quand le serveur doit faire face à une charge très importante ayant tendance à dégrader ses temps de réponse habituels.
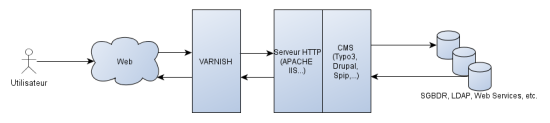
Architecture générale d’un proxy inverse
3. Les applications éligibles
Dans quel cas utiliser Varnish ?
Intéressons-nous tout d’abord aux capacités d’un outil comme Varnish.
Elles sont principalement les suivantes :
- c’est un système de cache permettant de soulager un serveur d’applications générant des contenus dynamiques ;
- c’est un point d’entrée unique de l’application, permettant d’ajouter une couche d’abstraction supplémentaire entre Internet et le serveur cible, et donc, avec une configuration adéquate, de renforcer la sécurité de l’architecture ;
- c’est un outil de répartition de charge : Varnish intègre une fonction de répartition de charge qui peut être intéressante si l’on dispose de plusieurs machines et que le choix d’un mécanisme de répartition n’a pas été réalisé.
D’un point de vue architecture, il ne faut pas oublier que Varnish est une solution Open Source avant tout destinée à la communauté Linux. Plus particulièrement, les versions pré-compilées comprennent les distributions Debian, FreeBSD, Red Hat et Ubuntu. Pour l’utiliser, il faut donc que le projet rentre dans ce premier cadre. Avec l’utilisation d’un serveur Web IIS par exemple, ceci implique notamment le choix d’un serveur Linux hébergeant Varnish en amont. Il est possible en théorie de faire fonctionner Varnish dans un environnement Windows, en s’appuyant notamment sur le projet Cygwin, portage de librairies Linux sous Windows. Mais en l’état, ce n’est pas la configuration que nous recommanderions.
L’ajout d’une couche supplémentaire dans une architecture n’est pas anodin. Il s’agit d’un coût non négligeable. Les coûts d’apprentissage, de maintenance et d’exploitation ne sont pas énormes mais viennent s’ajouter à la globalité du projet, et sur des sites un peu complexes, il faudra probablement prévoir de solliciter l’équipe projet, si possible en amont, pour que le développement soit bien compatible avec l’utilisation de Varnish.
Mettre en œuvre Varnish se justifie principalement quand les temps de réponse obtenus sur l’exécution d’un test de montée en charge ne sont pas satisfaisants par rapport aux objectifs de la maîtrise d’ouvrage, ou encore, si en cours d’exploitation d’une application, celle-ci ne parvient plus à faire face à la charge qu’elle reçoit.
Varnish ne peut évidemment mettre en cache que du contenu commun à tous les utilisateurs. Si l’application est à 100% personnalisée en fonction du profil utilisateur connecté, ce n’est probablement pas la meilleure solution à utiliser pour améliorer les performances, à moins que ce contenu personnalisé soit vraiment localisée dans un bout de page, comme une barre de profil dans un entête par exemple.
4. Fonctionnement
L’installation de Varnish est on ne peut plus simple, qui plus est si l’on s’appuie sur l’une des distributions Linux pour lesquelles une pré-compilation est disponible. Il n’y a rien de spécifique à l’installation de Varnish, à savoir une installation du package suivie d’une configuration du service.
Les principaux paramètres sur lesquels il est possible de jouer au démarrage du service sont les suivants :
- le type de mécanisme de cache : Varnish peut utiliser un cache mémoire ou un cache fichier ;
- la taille de cache allouée : il y a là un petit calcul à faire par rapport à la taille du contenu que l’on souhaite mettre en cache. On exclut généralement les ressources statiques car le serveur Web derrière est assez performant pour les servir seul ;
- une IP et un port d’administration : permet à l’administrateur de passer des commandes d’administration sans arrêter le service ;
- une IP et un port d’écoute : le point d’entrée de l’application.
Toute la configuration se fait ensuite dans un fichier, dans un langage propriétaire spécifique à Varnish, mais qui ressemble beaucoup à ce qui se fait ailleurs.
La configuration permet d’agir sur le cycle de vie d’une requête, chaque étape de ce cycle de vie disposant d’une fonction correspondante permettant d’affiner le comportement de Varnish.
Schématiquement et en simplifiant, ces intercepteurs évènementiels sont les suivants :
- vcl_recv : première étape d’une requête entrante, permet notamment de décider si le contenu doit être servi ou pas, et si oui comment (permet par exemple de forcer le cache ou de ne surtout pas cacher tel type de contenu).
- vcl_fetch : quand une requête entrante sollicite un contenu qui n’est pas dans le cache, Varnish la passe au serveur cible, et cet intercepteur évènementiel permet de définir le comportement à appliquer au retour de ce contenu (permet par exemple de définir en fonction de certains éléments comme des cookies si on veut cacher ou pas le contenu).
Ce sont les deux principaux évènements sur lesquels agir, mais il est également possible en cas de besoins plus poussés d’intercepter les évènements suivants :
- vcl_pass : cas où l’on renvoie la réponse au client sans passer par la vérification ni la mise en cache
- vcl_hit : étape intermédiaire où l’on vient de trouver le contenu demandé dans le cache
- vcl_miss : étape intermédiaire où l’on ne trouve pas le contenu demandé dans le cache
- vcl_deliver : étape intermédiaire où l’on va renvoyer côté client le contenu remonté du cache
- vcl_error : étape intermédiaire où une erreur est survenue
Pour les curieux qui veulent se faire peur, voici un lien qui permettra de consulter le schéma un peu plus évolué du cycle de vie officiel d’une requête dans Varnish : http://www.varnish-cache.org/trac/wiki/VCLExampleDefault
Dernier point fondamental de la configuration, la déclaration des serveurs cibles, à travers la directive « backend » : il s’agit des serveurs que Varnish va pouvoir solliciter pour aller chercher le contenu. On y déclare le domaine ou l’adresse IP ainsi que le port du serveur cible. Le serveur cible peut être local comme distant ce qui est pratique sur une architecture comprenant plusieurs machines.
Plusieurs serveurs cibles peuvent être déclarés, soit parce que le serveur Varnish est utilisé pour plusieurs applications différentes, soit parce que le serveur Varnish est configuré pour faire de la répartition de charge en fonction des différents serveurs cibles disponibles (cinq à six algorithmes sont possibles pour ce faire, de l’aléatoire à l’affectation d’un serveur à un client sur la durée de sa session en passant par le round-robin).
Exemple de configuration simple :
|
1 2 3 4 5 6 7 8 9 10 11 12 |
backend www { .host = "127.0.0.1"; .port = "8001"; } sub vcl_recv { return(lookup); } sub vcl_fetch { return(deliver); } |
On configure ici un serveur cible local sur le port 8001 (notre Varnish est lui configuré sur le port 80 Web classique). Lorsque la requête entre, on regarde si celle-ci est en cache pour éventuellement la servir directement (instruction « lookup »). A la récupération d’un contenu du serveur backend, ce contenu est caché et renvoyé au demandeur (instruction « deliver »). Avec cette configuration, Varnish va tenter de mettre en cache toutes les requêtes entrantes, en dehors de celles qu’il définit par principe comme non éligibles au cache (présence de cookie, d’authentification HTTP, etc.).
Voici ci-dessous quelques outils pratiques pour l’utilisation et l’exploitation de Varnish, tous à utiliser en ligne de commande :
VarnishTop : statistiques façon top Linux, qui présentent les évènements de trace les plus récurrents par ordre d’importance.
Exemple des informations rendues par VarnishTo
VarnishStat : ensemble de compteurs comme le nombre de requêtes, le nombre de requêtes envoyées depuis le cache, le nombre de requêtes envoyées au backend, etc.
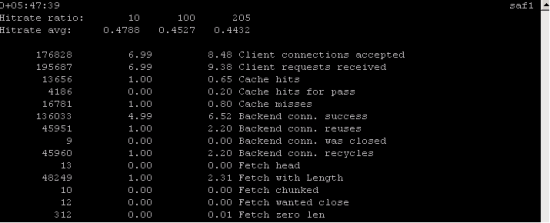
Exemple des informations rendues par VarnishStat
VarnishLog : l’accès au log détaillé de Varnish se trouve être une file mémoire qui se purge au fur et à mesure qu’elle se remplit. Il est possible de la diriger vers un fichier et de filtrer son contenu.
Exemple des informations rendues par VarnishLog
VarnishHist : histogramme permettant de suivre en secondes le temps mis par Varnish pour desservir le contenu, qu’il provienne du cache ou non.
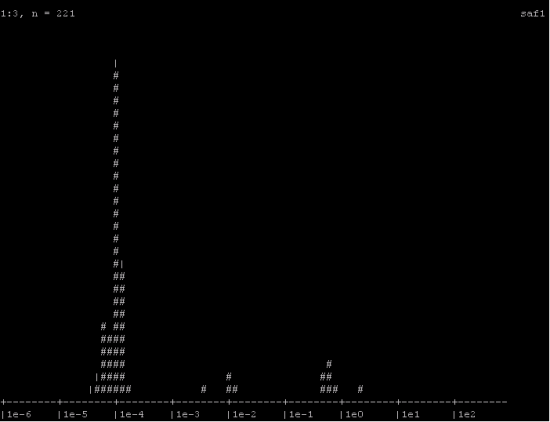
Exemple des informations rendues par VarnishHist
5. Démonstration
Un petit exemple étant toujours le bienvenu, nous travaillons actuellement sur un portail Web qui vise le million de hits par mois. Ce n’est pas encore l’audience du site d’un grand quotidien, mais cela représente tout de même un trafic conséquent à gérer.
Ce site s’appuie sur l’outil de gestion de contenu Typo3, un outil Open Source, parfait pour la structuration et l’alimentation du contenu, mais qui comme la majorité des outils de ce type, pêche en terme de performances sur la génération des pages finales envoyées côté utilisateur.
Bien que l’architecture à première vue soit assez simple, les impacts sur les performances peuvent être multiples et provenir :
- du code source de l’outil de gestion de contenu ;
- de la configuration apportée à Apache ;
- de la configuration apportée à PHP ;
- de la configuration apportée à MySQL ;
- de la configuration système (nous sommes dans ce cas précis sur une distribution Linux Ubuntu montée en configuration serveur) ;
- du chemin réseau pour accéder à la machine ;
- de la configuration apportée à Varnish ;
- du matériel CPU et RAM du serveur exécutant l’ensemble de cette architecture.
Nous passons également sur le fait qu’en production, nous avons un ensemble d’équipements réseaux intermédiaires et un équipement de répartition de charge car nous disposons de deux frontaux et d’un serveur de base de données.
Tout ça pour dire que l’optimisation d’une telle architecture ne s’improvise pas et nécessite de bien s’intéresser à toutes les briques entrant en jeu.
Pour aujourd’hui, nous allons nous limiter à mesurer le gain constaté avec l’utilisation de Varnish.
Nous utiliserons pour cette démonstration un petit outil d’automatisation de requêtes HTTP très pratique, JMeter, parfait pour jouer des scenarii et en mesurer les résultats.
En terme de scénario, huit requêtes seront testées, essentiellement les pages principales et pour se donner une idée, une feuille de style CSS, une image, et un fichier audio.
- la page d’accueil ;
- une page de liste d’articles ;
- une page d’article détaillée ;
- une page d’authentification ;
- une page d’accès à un contenu personnalisé ;
- la feuille de style principale de l’application ;
- une image de fond ;
- un fichier audio.
Dans ce scénario, les deux pages d’authentification et d’accès à un contenu personnalisé ne seront jamais mises en cache car elles nécessitent un contenu propre à chaque utilisateur. On devrait donc obtenir un temps sensiblement égal, que l’on mette en place la solution Varnish ou non sur ces deux pages.
Voici le tableau des résultats obtenus sans Varnish :

Temps obtenus pour 5 utilisateurs virtuels simultanés et 5 itérations de chaque étape, sans Varnish.
Et le tableau obtenu pour le même scénario avec Varnish :
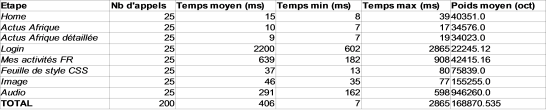
Temps obtenus pour 5 utilisateurs virtuels simultanés et 5 itérations de chaque étape, avec Varnish.
Le script a été joué 5 fois pour 5 utilisateurs virtuels, soit 25 requêtes pour chaque page.
Le résultat est particulièrement édifiant dans le cas de l’utilisation du CMS gourmand en ressources.
Les trois premières pages mettent sans Varnish un temps considérable à être générées par le CMS, entre 2,5 et 3,5 secondes. Avec Varnish, on obtient des temps de 10 à 15 ms, soit un gain de près de 99%.
Les deux pages qui suivent sont liées à la session de l’utilisateur et ne peuvent donc pas être cachées car elles sont personnalisées pour chaque utilisateur. On note tout de même une légère amélioration, de l’ordre de 20%, probablement due à l’allègement du nombre de requêtes envoyées au CMS pour les autres pages.
Pour la feuille de style, l’image, et le fichier audio, les résultats sont moins probants, voire contre-productifs. Varnish semble ajouter un léger temps de traitement et s’avère juste autant voire moins efficace que le serveur Apache pour restituer les ressources statiques.
6. Anticiper
Nous venons donc de voir le fonctionnement de Varnish, et tout l’intérêt de la mise en œuvre de ce type de solution.
Dans la majorité des cas cependant, les solutions de reverse proxy sont déployées un peu en urgence, généralement après la mise en production, et pour faire face à de mauvaises performances.
Il est toutefois possible d’en prévoir l’intégration dans l’architecture d’un site ou d’une application bien en amont, dès la phase de conception du projet.
Tout site destiné à une audience de type Internet potentiellement importante devrait prévoir la mise en place d’une telle solution.
Ce travail peut s’anticiper, notamment au travers de la norme ESI du W3C initiée à l’origine par la société Akamai, spécialisée dans ces problématiques de cache et de performances.
Cette norme reprend un peu les principes des balises frame du langage HTML, passées de mode aujourd’hui, ou de la balise iframe de ce même langage plus répandue.
Ce principe consiste à découper la structure d’une page HTML en différentes sections. En HTML, les balises frame et iframe permettent au développeur de mutualiser le code de certains contenus comme des barres de navigation ou des contenus répétés sur plusieurs pages. Cela permet aussi d’optimiser les échanges entre le navigateur client et le serveur en décidant de ne rafraîchir que le contenu de l’une des sections à un moment donné.
La norme ESI reprend au profit des solutions de reverse proxy cette notion de section de page à travers la balise , seul concept de la norme appliqué par Varnish.
A travers cette balise, simplement glissée dans le code HTML comme une balise frame ou iframe, on indique à Varnish qu’il faut aller inclure un contenu en référençant une adresse URL.
En découpant ainsi son contenu, on peut affiner la gestion du cache de Varnish en indiquant quelles sections peuvent être cachées et quelles sections ne doivent pas l’être (indispensable pour gérer des contenus spécifiques à un utilisateur ou une durée de cache courte pour une section « dernières nouvelles » d’un site d’actualités par exemple).
Imaginons ainsi une page composée de trois blocs :
|
1 2 3 4 5 6 7 |
<html> <body> <div id="bloc1">Contenu spécifique utilisateur : hello Michel !</div> <div id="bloc2">Les dernières news qui tombent toutes les 2 minutes</div> <div id="bloc3">Les 5 news les plus consultées hier (calculé la nuit)</div> </body> </html> |
Dans un mode normal, il est impossible de cacher cette page avec Varnish, chaque utilisateur devant voir son propre nom affiché et non pas celui du premier utilisateur à avoir demandé la page.
Pourtant, il serait bien pratique pour faire face à une montée en charge importante de pouvoir cacher le bloc 2 durant 2 minutes et le bloc 3 durant 24h. Pour ce faire, deux solutions s’offrent à nous :
- utiliser un iframe classique HTML en incluant deux pages complémentaires, une pour le bloc 2 et une pour le bloc 3;
- utiliser une balise ESI permettant d’inclure ces deux pages complémentaires.
La différence entre les deux solutions réside dans l’endroit où le contenu final sera assemblé. Dans le cas de la balise iframe, c’est le navigateur client qui assemble les deux blocs au contenu de la première page. L’inconvénient en cas de contenu un peu lourd à charger se traduit par un syndrome visuel de page qui s’affiche par morceaux. L’avantage de cette approche est le respect de la norme HTML classique. Le jour où l’on n’utilise plus Varnish, le site continue de fonctionner sans aucune modification. Dans le second cas, c’est Varnish qui assemble le contenu, en toute transparence pour le navigateur client qui a l’impression de ne recevoir qu’un flux HTML ininterrompu.
Le code ci-dessus avec ESI peut devenir par exemple :
|
1 2 3 4 5 6 |
<html><body> <esi src="http://example.com/bloc1" /> <esi src="http://example.com/bloc2" /> <div id="bloc3">Les 5 news les plus consultées hier (calculé la nuit)</div> </body> </html> |
Mais côté navigateur ce sera bien le même code de départ qui sera affiché :
|
1 2 3 4 5 6 7 |
<html> <body> <div id="bloc1">Contenu spécifique utilisateur : hello Michel !</div> <div id="bloc2">Les dernières news qui tombent toutes les 2 minutes</div> <div id="bloc3">Les 5 news les plus consultées hier (calculé la nuit)</div> </body> </html> |
7. Retour d’expérience
Voici quelques retours d’expérience sur l’utilisation de Varnish :
- Sur la configuration, le mode mémoire semble plus efficace que le mode fichier, mais il convient bien sûr de disposer de suffisamment de mémoire vive en fonction de la volumétrie du contenu que l’on souhaite mettre en cache.
- Des tests que nous avons pu mener, le cache des ressources statiques est légèrement moins performant que leur desserte directe par un serveur efficace comme Apache.
- Ne pas perdre de vue que le fichier de configuration VCL doit rester le plus simple possible au risque de ne plus parvenir à le maintenir.
- Essayer de penser le cache le plus en amont possible dans la conception du projet afin de pouvoir cacher le maximum de contenu en utilisant éventuellement une balise iframe ou la norme ESI.
- Avoir une vision globale de son application : il ne faut pas hésiter à définir des durée de vie du cache par typologie de contenu, et ne pas oublier de tenir compte de petites subtilités comme d’une différence d’affichage en fonction d’un cookie, d’un nom d’hôte, ou d’un entête HTTP comme dans le cas d’un contenu adapté à un accès via un terminal mobile.
- Bien vérifier avec un outil tel que JMeter que sa propre configuration est efficace car certains éléments qui ne sautent pas immédiatement aux yeux peuvent empêcher la mise en cache du contenu, comme des cookies renvoyés inutilement par la solution de gestion de contenu par exemple. Ne pas hésiter dans ce cas à supprimer les cookies intempestifs grâce aux possibilités de Varnish d’agir sur les entêtes HTTP en entrée comme en sortie.
- Exécuter Varnish sur un serveur 64 bits car il a été conçu pour cette architecture, qui plus est si on utilise le mode mémoire à plus de 3Go.
- Ne pas se laisser rebuter par les logs de VarnishLog, celles-ci permettant de bien comprendre ce qu’il se passe en cas de dysfonctionnement.
8. Les limites
Varnish est un outil redoutablement efficace. Ceci étant, il ne faut pas perdre de vue qu’il n’est qu’une brique de l’application qui a été mise en place. Si Varnish est souvent utilisé en tant que « cache misère », ce n’est pas une raison pour ne pas essayer de bien concevoir l’application à mettre en cache, d’autant qu’à chaque expiration du cache, le premier utilisateur verra le vrai visage du site.
Il ne faut pas non plus oublier que Varnish n’est d’aucune utilité dans le cadre de contenu fortement personnalisé, et que, par conséquent, il n’est pas adapté à tous les contextes.
Dans notre retour d’expérience, nous avons noté également quelques limites dans les possibilités de manipulation des cookies échangés entre client et serveur, avec notamment la possibilité de ne pouvoir accéder qu’au premier des cookies dans le cas d’échange de cookies multiples.
Il faut aussi faire attention pour les sites utilisant un certificat SSL. Dans la mesure où le reverse proxy se trouve en première ligne face au navigateur client, c’est généralement vers lui que doit se déplacer la gestion du certificat SSL. Or, Varnish ne dispose pas de version supportant le protocole SSL actuellement. Il faut alors ajouter un proxy SSL comme Nginx ou Pound à son architecture en amont du reverse proxy Varnish. C’est la limite majeure que nous avons trouvée dans l’utilisation de cette solution.
L’utilisation de Varnish nécessite tout de même quelques solides connaissances en terme d’architecture Web et de fonctionnement d’une application de ce type. Sa configuration ne dispose d’aucun outil graphique, tout se faisant en ligne de commande et par fichier de configuration. La conclusion est identique pour les outils de traces et d’analyse du comportement de Varnish : il faut un peu de temps avant de comprendre leur fonctionnement et savoir tirer parti des informations restituées.
Pour autant, une fois ces quelques freins passés, Varnish s’avère être un outil très efficace, pouvant rendre service à beaucoup d’applications à forte audience.
9. Varnish 3.0
La version 3.0 de Varnish est sortie le 17 juin. Bien que nous n’ayons pas encore suffisamment de recul sur les améliorations de cette nouvelle version, en voici quelques aperçus. Il n’y a pas de révolution notable apportée. Les principaux changements portent sur un meilleur support des mécanismes de compression/décompression, une configuration par défaut optimisée, une amélioration des outils de supervision et de trace ainsi qu’un enrichissement de la documentation.
10. Références
Site officiel : http://www.varnish-cache.org
Définition d’un reverse proxy sur Wikipedia : http://fr.wikipedia.org/wiki/Reverse_proxy
Bonnes pratiques : http://kristianlyng.wordpress.com/2010/01/26/varnish-best-practices
Norme ESI, site officiel : http://www.w3.org/TR/esi-lang
ESI appliqué à Varnish : http://www.varnish-cache.org/trac/wiki/ESIfeatures