L’ETL (« Extract Transform Load ») est une technologie permettant l’échange et la synchronisation de données issues de bases de données ou de fichiers vers une autre structure. A l’origine, cette technologie était utilisée pour faciliter la sauvegarde régulière de bases de données avant de peu à peu élargir son champ d’action vers d’autres aspects, notamment pour solutionner le grand nombre d’interfaces existantes.
Les bases de données concernées par l’ETL peuvent donc être de type différent et, pendant la synchronisation, diverses modifications peuvent être apportées sur les données (jointures, encodages, tris …).
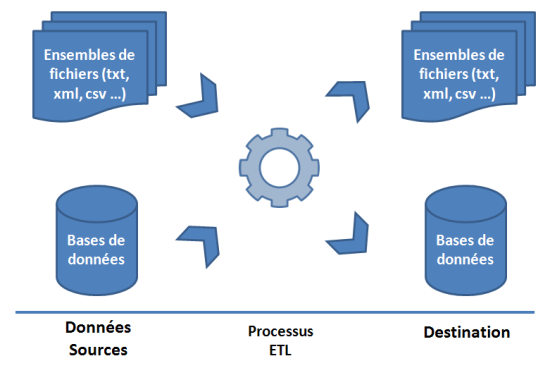
Figure 1 : objectifs de l’ETL
Dans cet article, nous allons plus précisément nous intéresser à l’outil ETL open source développé par la société Talend, en traçant les grandes lignes des fonctionnalités proposées puis en présentant quelques exemples d’utilisation.
1. Présentation de Talend Open Studio
1.1 Le logiciel
« Talend Open Studio » est un outil d’intégration de données open source distribué depuis 2006 sous la licence GNU General Public License (GPL) par la société Talend. Talend Open Studio est basé sur la plateforme Eclipse et peut être installé sur les systèmes d’exploitation Linux et Windows.
La société propose également une version payante nommée « Talend Integration Suite ». Les différences majeures entre ces deux versions se situent principalement autour de la gestion, du déploiement et de l’exécution des tâches. En effet, la version payante prend en charge la gestion de configuration avec la possibilité d’utiliser un gestionnaire de sources (principalement CVS ou SVN) ainsi qu’une solution de supervision des flux intégrée à Eclipse ou en version Web.
1.2 Le principe
Ce logiciel fonctionne comme un générateur de code : pour chaque traitement d’intégration de données, un code spécifique est généré, ce dernier pouvant être en Java ou en Perl. Les opérations effectuées par le logiciel sont appelées « Jobs » et sont conçues par l’utilisateur grâce à une interface graphique : le « Job Designer ».
Talend Open Studio supporte, en lecture et en écriture, la plupart des SGBD (MySQL, MS SQL Server, DB2, PostgreSQL, Oracle, …) ainsi que certains formats de fichier (CSV, Excel, XML, …). Le logiciel facilite la création de requêtes en s’appuyant sur une détection automatique du schéma de la base de données. De plus, tous les schémas de données créés ainsi que les connexions définies sont réutilisables pour d’autres Jobs afin de rendre la mise en place plus rapide.
1.3 Les opérations disponibles
Au niveau des opérations disponibles, Talend propose une palette étendue d’objets et de connecteurs (environ 400 éléments) que l’utilisateur peut associer facilement via l’interface graphique. Ces éléments se combinent avec la majorité des SGBD supportés et offrent un large panel de fonctionnalités : jointures, encodage, multiplexage …
A cette librairie d’opérations s’ajoute la possibilité de créer des routines. Les routines sont en réalité des fonctions écrites en langage Java pour lesquelles les paramètres d’entrée et de sortie sont définis pour s’adapter aux données à transformer. Cette approche ouvre largement le champ de fonctionnalités supportées nativement par le logiciel.
L’interface graphique offre en plus la possibilité de suivre l’exécution des Jobs en temps réel tout en indiquant des statistiques sur le déroulement de la tâche telles que le nombre de lignes traitées ou encore la vitesse de l’opération en nombre de lignes par seconde.
2. Exemple de création d’un job
Afin d’illustrer le fonctionnement de la solution Talend Open Studio, utilisons un exemple de migration simple.
Nous disposons d’une base de données Microsoft SQL Server comportant diverses tables relatives au fonctionnement d’une application. Parmi ces tables, nous souhaitons exporter de manière régulière celle comportant des données sensibles : les coordonnées de nos clients. Comme format d’export, le choix s’est porté sur un fichier XML dont la structure est décrite dans le schéma récapitulatif suivant :
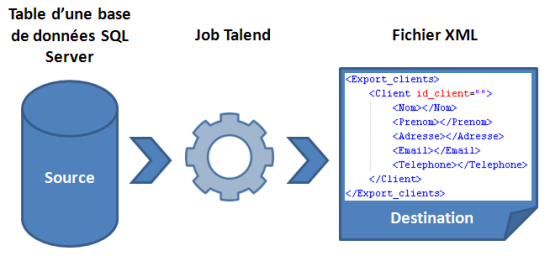
Figure 2 : notre cas d’étude
2.1 Les données source
Préalablement à la création de cette tâche, nous allons créer une connexion vers la source de données, dans notre cas une base Microsoft SQL Server. Cette opération se réalise via l’onglet Référentiel > Métadonnées > Connexions > Créer une connexion. Il suffit ensuite de choisir le type de base de données que l’on souhaite utiliser puis de régler les paramètres de connexion.
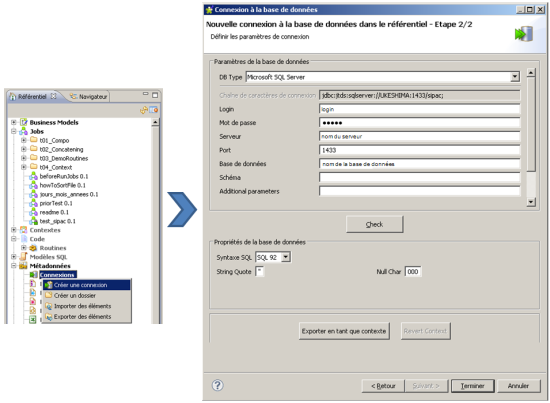
Figure 3 : création de la connexion vers la base de données
L’étape suivante consiste à fournir au logiciel le schéma de la table que l’on souhaite exporter. Cette opération est relativement simple dans ce cas car le schéma peut directement être récupéré depuis la connexion à la base. Après avoir sélectionné la table concernée, les colonnes sont automatiquement détectées.
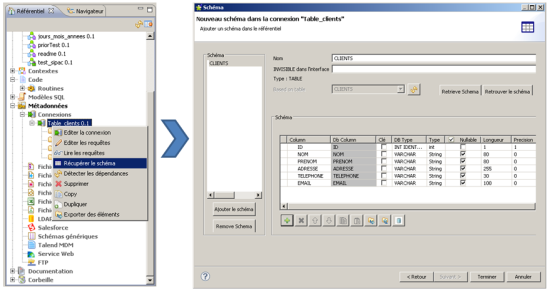
Figure 4 : export du schéma de la table ciblée
Une fois le schéma enregistré, il ne reste plus qu’à écrire la requête SQL pour obtenir les données souhaitées. Cette action est également simplifiée, un assistant proposant en effet de générer cette clause automatiquement en sélectionnant la table définie précédemment.
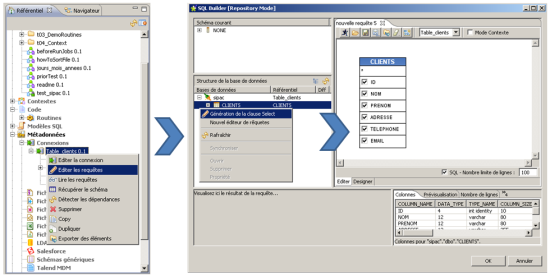
Figure 5 : mise en place de la clause de sélection des champs à exporter
Remarque : le référentiel est commun à tous les jobs. Il est ainsi possible de réutiliser cette connexion pour de nombreux projets.
2.2 Création du job
Au cours de l’étape précédente, nous avons mis en place une connexion à la base de données utilisable par tous nos projets. Il faut maintenant créer le job représentant la tâche d’exportation à proprement parler. Talend Open Studio permet de définir les jobs via le Job Designer, interface graphique permettant de disposer des éléments issus de la palette d’objets. Le logiciel génère parallèlement le code correspondant à la tâche réalisée graphiquement par l’utilisateur.
La création d’un job se fait via un clic droit sur la section « Jobs » de l’onglet « Référentiel ». Une fois celui-ci ouvert, l’interface graphique et la palette d’objets proposés par le logiciel prennent place à l’écran.
Afin de réaliser notre exemple décrit précédemment, nous allons dans un premier temps mettre en place l’objet qui, lors de l’exécution du job, rapatriera les données depuis la base SQL. Pour cela, la palette propose sous l’onglet « Bases de données » une liste des SGBD supportés. Pour notre exemple, nous ouvrons la rubrique « MS SQL Server » puis nous plaçons sur la zone de création graphique une source de données : l’objet « tMSSqlInput ».
Les objets ajoutés depuis la palette ne sont par défaut pas configurés. Un double clic sur ceux-ci ouvre cependant le panneau « Component » qui permet de les paramétrer. Ici, notre base de données a été définie préalablement. Il suffit donc de sélectionner à l’aide des listes déroulantes les informations correspondantes à la connexion.
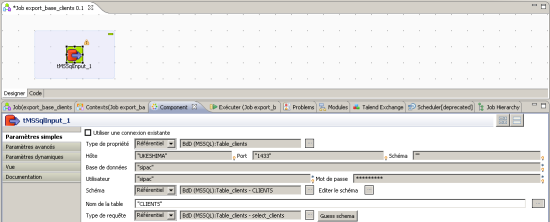
Figure 6 : configuration de l’objet « tMSSqlInput » selon la connexion définie précédemment
Notre source de données étant paramétrée, il faut alors mettre en place l’objet permettant d’écrire le fichier XML de sortie. Pour cela, la palette propose sous l’onglet « Fichiers » un objet nommé « tAdvancedFileOutputXML » que nous plaçons également sur l’interface graphique.
Concernant les réglages de cet objet (appelé aussi bloc), il n’est pas possible ici d’importer une configuration depuis le référentiel. Les paramètres doivent donc être entrés manuellement via le panneau « Component » :
- Il est nécessaire de spécifier le chemin et le nom du fichier XML de sortie.
- Il faut également préciser au bloc la structure des données à son entrée pour que l’on puisse lier les champs extraits de la base SQL aux tags XML correspondants lors de l’étape suivante. Pour cela, on réutilise le schéma créé lors de l’étape précédente en le sélectionnant depuis le référentiel via une liste déroulante.
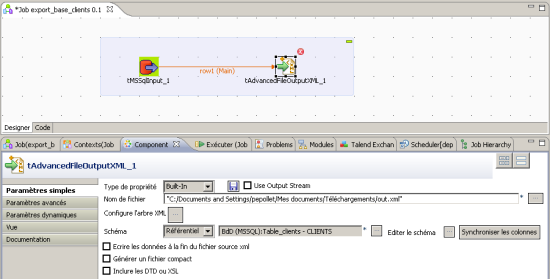
Figure 7 : mise en place du bloc de sortie
Le bloc « tAdvancedFileOutputXML » dispose dorénavant du schéma des données entrantes. Il faut ensuite lui fournir la structure XML sur laquelle se baser pour obtenir le format que nous souhaitons en sortie. Nous construisons un schéma XML à cet effet :

Figure 8 : schéma XML de sortie
Le bouton « Configurer l’arbre XML » ouvre une fenêtre permettant d’importer notre schéma. Ceci fait, la fenêtre se met à jour et affiche sur la partie gauche le schéma des données entrantes et sur la droite les marqueurs placés dans le schéma XML. Nous pouvons alors mapper ces éléments par glissé-déposé depuis les entrées vers les sorties.
Enfin, nous définissons la balise Client de notre schéma XML comme « élément boucle » : la portion du schéma contenue dans ce nœud sera réutilisée autant de fois que de lignes SQL issues de la table.
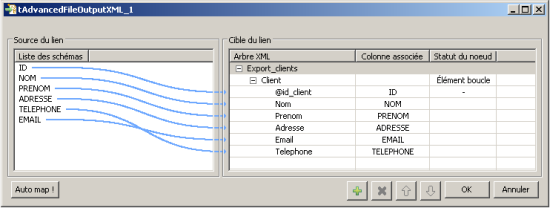
Figure 9 : mappage entrées / sorties
2.3 L’exécution
A l’exécution du Job, les statistiques apparaissent sur les éléments graphiques de l’interface.

Figure 10 : statistiques d’exécution
Dans le dossier de sortie, nous obtenons un fichier XML avec les informations de la base de données mappées sur le schéma fourni précédemment.
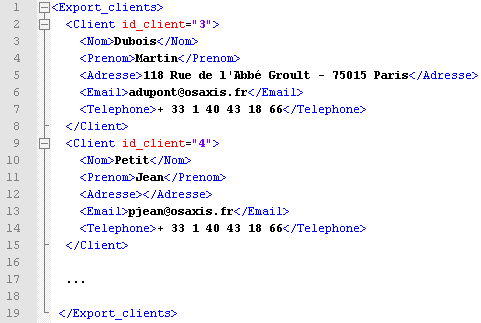
Figure 11 : le fichier de sortie
3. Présentation de quelques opérations disponibles
3.1 Les fonctions intégrées
Parmi les fonctions intégrées nativement, on retrouve un module permettant d’enregistrer des logs depuis n’importe quelle connexion du Job.

Figure 12 : utilisation de l’objet tLog au centre de notre exemple
On retrouve également des fonctions de tri, de recherche… mais aussi des outils plus génériques tels que l’objet « tMap » qui offre une multitude de possibilités via sa configuration. Il permet notamment d’effectuer des jointures de données, des traitements simples sur les chaînes de caractères ainsi que la possibilité d’appliquer une fonction définie par l’utilisateur.
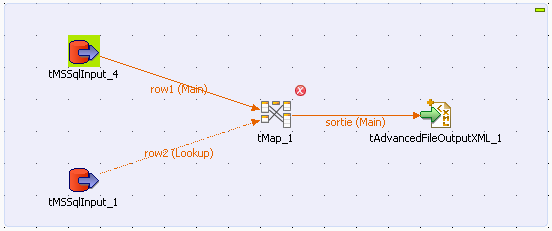
Figure 13 : mise en place d’un bloc tMap reliant deux sources de données
3.2 Création de routines
Les routines sont des fonctions Java codées par l’utilisateur dans le but d’appliquer un traitement particulier aux données. Pour créer une routine, il faut ajouter un élément sous la section Code > Routines de l’onglet Référentiel.
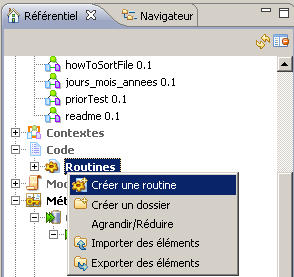
Figure 14 : création de la routine
Un éditeur de code Java laisse alors la possibilité d’écrire la fonction de son choix, en prenant garde aux entrées sorties de la fonction afin que cette dernière soit utilisable avec le schéma de données utilisé. Il faut alors placer un bloc tMap à l’endroit désiré.

Figure 15 : l’objet tMap qui permet d’appliquer la routine aux données
Lors de l’édition des préférences, une fenêtre de mappage apparaît. Si la source et la destination sont correctement configurées, l’utilisation de la fonction « Auto Map » réalise le paramétrage des connexions du bloc tMap automatiquement. Pour appliquer la routine, on utilise le bouton « … » à coté du champ concerné.
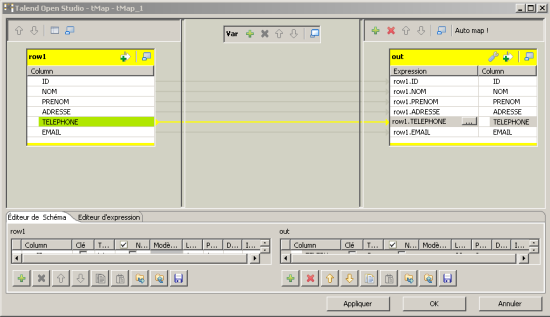
Figure 16 : mappage des données entrantes et sortantes du bloc tMap
Un nouvel écran propose alors comment traiter cet élément via une liste de fonctions combinant celles définies par l’utilisateur et celles existant nativement.
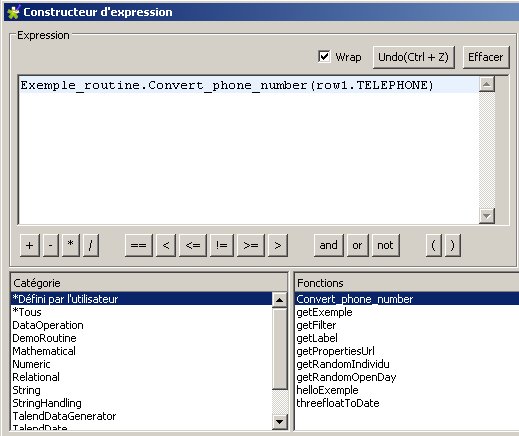
Figure 17 : application de la routine sur la colonne « TELEPHONE »
4. Exporter un job
Avec Talend Open Studio, l’export des Jobs créés depuis l’interface graphique est très simple. Il consiste en effet à effectuer un clic droit sur un job fonctionnel puis de sélectionner « exporter le job » afin d’obtenir une copie complète de la tâche. Cette dernière peut ensuite être exécutée depuis plusieurs plateformes. En effet, on retrouve dans le répertoire de l’export deux fichiers d’extensions .bat et .sh ainsi que toutes les ressources nécessaires au fonctionnement du job.
Conclusion
Talend Open Studio propose les fonctionnalités essentielles d’un outil ETL moderne (concepteur graphique, grand nombre d’outils de traitement, statistiques d’exécution …) et offre une utilisation accessible rapidement aux utilisateurs. Mais cette solution open source ne peut concurrencer les versions payantes des grands acteurs du marché tels qu’IBM, Oracle … qui fournissent des outils supplémentaires.
On se tournera donc, pour des projets de plus grande échelle, vers la version payante de la suite qui propose entre autre un outil de nettoyage des données, des interfaces de connexion aux services d’annuaires, une console de supervision des flux, un gestionnaire de sources… ainsi qu’une grande quantité d’autres fonctionnalités complémentaires.