Introduction
Lorsqu’il s’agit de récupérer des données depuis une base relationnelle et de manipuler les objets correspondants, il est souvent fait mention des ORMs.
L’utilisation d’un ORM n’est pas toujours la solution retenue ou la plus adaptée et dans l’univers Java, la solution la plus directe est l’interface JDBC. Cependant, l’utilisation de cette API de bas-niveau peut s’avérer fastidieuse.
JDBI propose un accès pratique et idiomatique aux bases de données relationnelles par l’intermédiaire de JDBC. La version de JDBI présentée ci-après est la version 3, tirant profit des fonctionnalités de la version 8 de Java.
Utilisation par l’exemple
Prenons pour exemple une application permettant de gérer des listes de courses. Une liste de courses se caractérise par un identifiant, un état (ouverte ou terminée), ainsi qu’un commentaire. Elle est composée de produits à acheter en une certaine quantité.
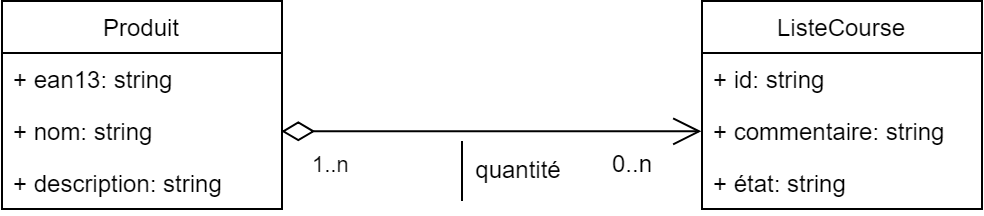
Figure 1 : Modèle de données
Ce modèle se traduit par le schéma SQL suivant :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
CREATE TABLE produit ( ean13 CHAR(13) NOT NULL CHECK(length(ean13) = 13), nom VARCHAR(100) NOT NULL, description VARCHAR(255) NOT NULL, PRIMARY KEY(ean13) ); CREATE TABLE liste_course ( id CHAR(36) NOT NULL CHECK(length(id) = 36), commentaire VARCHAR(255) NOT NULL, etat CHAR(8) NOT NULL CHECK(etat in ('OUVERTE', 'TERMINEE')), PRIMARY KEY(id) ); CREATE TABLE liste_course_item ( liste_course_id CHAR(36) NOT NULL CHECK(length(liste_course_id) = 36), produit_ean13 CHAR(36) NOT NULL CHECK(length(produit_ean13) = 13), quantite DECIMAL(10,2) NOT NULL, PRIMARY KEY(liste_course_id, produit_id), FOREIGN KEY(produit_ean13) REFERENCES produit(ean13), FOREIGN KEY(liste_course_id) REFERENCES liste_course(id) ); |
Connexion et démarrage
La classe JDBI est le point d’entrée de la librairie. Cette classe permet d’abstraire la source de données JDBC faisant référence à la base de données à utiliser.
Il est possible de créer cette instance grâce à une référence directe à la base de données ou encore d’utiliser une source de données et ainsi de pouvoir également bénéficier d’un pool de connexions :
|
1 2 3 4 5 6 7 |
// Création d’une instance JDBI directement connectée à la base de données JDBI jdbi = JDBI.create("jdbc:h2:mem:jdbi_article"); // Utilisation d’une source de donnée final Context ctx = new InitialContext(); final DataSource ds = (DataSource) ctx.lookup("Java:comp/env/jdbi"); JDBI jdbi = JDBI.create(ds); |
Premières requêtes
L’exécution de requêtes passe par la manipulation de l’objet « Handle », représentant une connexion active à la base de données.
Cet objet permet d’exécuter tous les types de requêtes ainsi que de gérer les transactions. Il fournit des méthodes chaînées (fluent API), permet d’associer les valeurs nécessaires aux arguments des requêtes, d’exécuter l’instruction SQL et d’en récupérer le résultat (sous forme d’objets ou types primitifs).
L’instruction « createUpdate » exécute une requête modifiant les données (Insert, Update ou Delete) et offre la possibilité de paramétrer les éléments de la requête.
|
1 2 3 4 5 6 7 8 |
// Insertion d’un enregistrement dans la table produit this.jdbi.useHandle(handle -> handle.createUpdate("INSERT INTO produit (ean13, nom, description) VALUES (:ean13, :nom, :description)") .bind("ean13", "1234567891011") .bind("nom", "Soda") .bind("description", "Soda rafraîchissant en bouteille") .execute() ); |
La récupération de donnée se fait de façon similaire avec la méthode « createQuery » :
|
1 2 3 4 5 6 7 8 9 10 |
// Récupération d’un produit grâce à sa clef primaire Produit soda = this.jdbi.withHandle(handle -> handle.createQuery("SELECT ean13, nom, description FROM produit WHERE ean13 = :ean13") .bind("ean13", "1234567891011") .map((resultSet, ctx) -> new Produit( resultSet.getString("ean13"), resultSet.getString("nom"), resultSet.getString("description"))) .findOnly() ); |
La méthode « findOnly() » considère que le résultat de la requête doit être composé d’une seule et unique ligne. Dans le cas contraire, une exception sera levée.
La méthode « findOne() » retourne la première ligne du résultat de la requête (si elle existe) sous la forme d’un « Optional ». Si le résultat contient plusieurs lignes, seule la première ligne est traitée, les autres sont ignorées.
Enfin une méthode « list() » récupère l’ensemble des lignes du résultat sous forme de liste. Cette liste peut être vide si le résultat de la requête l’est également.
Notons ici la différence entre les méthodes « useHandle » et « withHandle ». La méthode « useHandle » prenant en paramètre un « Consumer » ne renvoie aucun résultat, alors que la méthode « withHandle » attendant en paramètre un « Callback » permet le retour d’un résultat.
A noter également qu’il aurait été possible pour l’instruction d’insertion d’utiliser un « Callback » afin de récupérer le nombre d’éléments affectés par l’instruction « createUpdate » (retour de la méthode« execute() »). Cette fonctionnalité est particulièrement utile dans le cas d’une requête de mise à jour pour connaître le nombre d’enregistrements modifiés par la requête.
L’objet « Handle » propose aussi des méthodes pour les traitements « batch » avec « createBatch » et « preparedBatch » et l’exécution de procédures stockées avec « createCall ».
Paramétrage des requêtes
JDBI permet de spécifier les arguments des requêtes de plusieurs manières. La plus courante est la possibilité de valoriser les arguments par leur position (index) dans la requête, ou par leur nom.
|
1 2 3 4 5 6 7 8 |
// Paramétrage des éléments de la requête par leurs positions this.jdbi.useHandle(handle -> handle.createUpdate("INSERT INTO produit (ean13, nom, description) VALUES (?, ?, ?)") .bind(0, "1230565891412") .bind(1, "Eau gazeuse") .bind(2, "Bulles et fraîcheur") .execute() ); |
JDBI est également capable de lier la valeur des attributs d’un objet aux paramètres nommés de la requête.
|
1 2 3 4 5 6 7 |
Produit gateau = new Produit("1458752200125", "Gâteau moelleux", "Pur beurre"); this.jdbi.useHandle(handle -> handle.createUpdate("INSERT INTO produit (ean13, nom, description) VALUES (:ean13, :nom, :description)") .bindBean(gateau) .execute() ); |
Un objet est fourni pour le paramétrage de la requête. Les paramètres sont valorisés par les attributs de l’objet.
Une autre variante est d’utiliser une simple « Map » ayant pour clef le nom des paramètres.
|
1 2 3 4 5 6 7 8 9 10 11 |
// Utilisation d’une map avec pour clef le nom des paramètres Map<String, Object> params = new HashMap<>(); params.put("ean13", "1854785213654"); params.put("nom", "Dentifrice menthol"); params.put("description", "Prévient les carries"); this.jdbi.useHandle(handle -> handle.createUpdate("INSERT INTO produit (ean13, nom, description) VALUES (:ean13, :nom, :description)") .bindMap(params) .execute() ); |
Finalement, il est possible d’utiliser le résultat de l’appel des méthodes de l’objet, le nom du paramètre doit alors correspondre au nom d’une méthode de l’objet. Ce mécanisme est permis grâce à « bindMethods » et à la réflexion.
Ajouter à cela que les méthodes « bindBean » et « bindMethods » permettent d’accéder aux propriétés d’objets composant l’objet racine. En imaginant que l’objet « Produit » ait pour attribut un objet « Fabricant », il est possible de lier les paramètres aux valeurs de l’objet de cette manière :
|
1 2 3 4 5 6 7 |
// Utilisation de propriétés imbriquées à l’objet pour la définition de la valeur d’un paramètre this.jdbi.useHandle(handle -> handle.createUpdate("INSERT INTO produit (ean13, nom, description) VALUES (:p.ean13, :p.nom, :p.fabricant.descriptionParLeFabricant)") .bindBean("p", produit) .execute() ); |
Mappers
Lors de la récupération du résultat d’une requête, les enregistrements sont très souvent transformés en objet. Cette transformation est effectuée par l’instruction « .map() » comme illustré lors de la récupération de l’objet « soda » dans le chapitre « Premières requêtes ».
JDBI permet l’externalisation de ces opérations de mapping afin d’éviter de les définir à chaque instruction SQL.
JDBI distingue deux types de mapper, les « RowMapper » permettant de transformer une ligne du résultat de la requête en un objet et les « ColumnMapper » permettant de transformer une colonne de la ligne courante du résultat.
RowMapper
Les « RowMapper » sont de simples classes implémentant l’interface « RowMapper » et ayant une seule méthode « map ». La méthode « map » transforme une ligne de résultat en un objet du type défini par et pour ce mapper.
Exemple avec l’objet « Produit » :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
// Classe permettant la transformation d’une ligne de résultat en un objet de type « Produit » package fr.osaxis.jdbi.mapper; import Java.sql.ResultSet; import Java.sql.SQLException; import org.jdbi.v3.core.mapper.RowMapper; import org.jdbi.v3.core.statement.StatementContext; import fr.osaxis.jdbi.modele.Produit; public class ProduitRowMapper implements RowMapper<Produit> { @Override public Produit map(ResultSet rs, StatementContext ctx) throws SQLException { Produit resultat = new Produit(); resultat.setDescription(rs.getString("description")); resultat.setEan13(rs.getString("ean13")); resultat.setNom(rs.getString("nom")); return resultat; } } |
Pour que l’association soit effective, il faut déclarer lors de la configuration de l’instance JDBI que le « ProduitRowMapper » permet de transformer une ligne de résultat en un objet « Produit » :
|
1 2 |
// Inscription du mapper à l’instance JDBI this.jdbi.registerRowMapper(Produit.class, new ProduitRowMapper()); |
La récupération du produit « soda » peut être réécrite de la manière suivante :
|
1 2 3 4 5 6 7 |
// JDBI fait le lien entre le mapping demandé et le mapper associé au type. Produit soda = this.jdbi.withHandle(handle -> handle.createQuery("SELECT ean13, nom, description FROM produit WHERE ean13 = :ean13") .bind("ean13", "1234567891011") .mapTo(Produit.class) .findOnly() ); |
ColumnMapper
Les « ColumnMapper » sont similaires aux « RowMapper » et permettent de transformer une colonne depuis le type de l’enregistrement de la base de données vers un type Java.
Cependant leur intérêt est plus limité car ils ne peuvent s’appliquer qu’aux requêtes contenant une seule colonne dans leurs résultats. Dans le cas d’une requête ayant plusieurs colonnes, le mapper ne s’appliquera qu’à la première colonne.
Les cas d’usages peuvent concerner la conversion de données monétaires ou encore la transformation de valeurs d’énumération stockées sous forme de chaîne de caractères ou numérique.
Récupérer un graphe d’objets
Les jointures sont des opérations basiques en SQL. Mais lorsque qu’il s’agit de transformer un modèle relationnel en graphe d’objets, les problèmes commencent.
JDBI permet de récupérer tout un graphe d’objets à partir d’une seule requête, grâce à un mécanisme de « reduce » et d’un accumulateur.
Pour récupérer toutes les listes de courses, avec pour chaque liste, la collection des éléments la composant et les produits associés, on utilise la requête suivante :
|
1 2 3 4 5 6 7 8 9 10 |
SELECT lc.id AS lc_id , lc.commentaire AS lc_commentaire , lc.etat AS lc_etat , lci.quantite AS lci_quantite , p.ean13 AS p_ean13 , p.nom AS p_nom , p.description AS p_description FROM liste_course AS lc INNER JOIN liste_course_item AS lci ON lci.liste_course_id = lc.id INNER JOIN produit AS p ON p.ean13 = lci.produit_ean13 |
Grâce à une jointure sur la relation « 1..n » entre l’objet « ListeCourse » et l’objet « Produit », la requête va « exploser » toutes les composantes de chaque liste de course avec autant de lignes pour chaque « ListeCourse » que d’éléments la constituant.
Grâce à l’utilisation de la méthode « reduceRows » sur le résultat de la requête, il est possible de créer un graphe d’objets complet.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
List<ListeCourse> listeCourseList = this.jdbi.withHandle(handle -> handle.createQuery(listeCourseCompleteSql) .registerRowMapper(BeanMapper.factory(ListeCourse.class, "lc_")) .registerRowMapper(BeanMapper.factory(ListeCourseItem.class, "lci_")) /* 1 */ .registerRowMapper(BeanMapper.factory(Produit.class, "p_")) .reduceRows(new HashMap<String, ListeCourse>(), (accumulator, rowView) -> { /* 2 */ ListeCourse listeCourse = accumulator.computeIfAbsent( rowView.getColumn("lc_id", String.class), id -> rowView.getRow(ListeCourse.class) ); /* 3 */ ListeCourseItem listeCourseItem = rowView.getRow(ListeCourseItem.class); /* 4 */ listeCourseItem.setProduit(rowView.getRow(Produit.class)); /* 5 */ listeCourseItem.setListeCourse(listeCourse); /* 6 */ listeCourse.getItems().add(listeCourseItem); return accumulator; /* 7 */ }).values().stream().collect(Collectors.toList()) /* 8 */ ); |
Voici le détail des différentes étapes du traitement :
1. On indique à l’API l’enregistrement d’un mapper générique avec préfixe. Ce préfixe sert à déterminer l’appartenance d’un champ du résultat de la requête à un objet à créer. Ici, tous les champs préfixés par « lc_ » appartiennent à un objet « ListeCourse »
2. Cette instruction définit le traitement de « réduction » du résultat de la requête. L’accumulateur est initialisé avec une « Map » stockant les différentes listes de courses avec pour clef leur identifiant.
3. La liste de courses correspondante est extraite de la ligne du résultat si inconnue de l’accumulateur, ou récupérée de la map si connue.
4. L’item de la liste de courses est extrait de la ligne de résultat.
5. Le produit est également extrait de la ligne de résultat puis est assigné à l’item correspondant.
6. L’item est ajouté à la liste de courses courante.
7. L’accumulateur complété est retourné pour être fourni au parcours des lignes suivantes.
8. En fin de traitement, les listes de courses sont récupérées sous la forme d’une collection (ici une liste).
Interface DAO
JDBI possède un plugin nommé « SQLObject » afin de définir les opérations élémentaires des DAO. Les DAO prennent la forme d’interfaces spécifiant des méthodes publiques ainsi qu’une opération SQL associée pour chaque méthode.
L’exemple suivant montre comment définir et utiliser une interface DAO :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
//Exemple de classe DAO manipulable par JDBI package fr.osaxis.jdbi.dao; import Java.util.List; import Java.util.Optional; import org.jdbi.v3.core.transaction.TransactionIsolationLevel; import org.jdbi.v3.sqlobject.config.RegisterRowMapper; import org.jdbi.v3.sqlobject.customizer.Bind; import org.jdbi.v3.sqlobject.statement.SqlUpdate; import org.jdbi.v3.sqlobject.transaction.Transaction; import fr.osaxis.jdbi.mapper.ProduitRowMapper; import fr.osaxis.jdbi.modele.Produit; public interface ProduitDao { @SqlQuery("SELECT ean13, nom, description FROM produit WHERE ean13 = :ean13") @RegisterRowMapper(ProduitRowMapper.class) Optional<Produit> get(@Bind("ean13") String ean13); @SqlQuery("SELECT ean13, nom, description FROM produit") @RegisterRowMapper(ProduitRowMapper.class) List<Produit> list(); @SqlUpdate("INSERT INTO produit (ean13, nom, description) VALUES (:ean13, :nom, :description)") void insert(@Bind("ean13") String ean13, @Bind("nom") String nom, @Bind("description") String description); @SqlUpdate("INSERT INTO produit (ean13, nom, description) VALUES (:ean13, :nom, :description)") void insert(@BindBean Produit produit); } |
On retrouve dans la classe précédente les annotations suivantes :
• @SqlQuery et @SqlUpdate : de manière similaire aux méthodes « createQuery » et « createUpdate » de l’objet « Handle », ces deux annotations permettent de déclarer les instructions SQL et leurs types d’opérations (lecture, écriture).
• @RegisterRowMapper : cette annotation permet d’associer le « mapper » nécessaire à la transformation des lignes du « ResultSet » SQL en objets Java.
• @Bind : cette annotation permet de faire le lien entre le paramètre de la méthode et le paramètre de la requête SQL correspondante. Il est possible de se passer de cette annotation si le code source est compilé avec le paramètre « -parameters ». Cette option de compilation a pour effet de conserver le nom des paramètres remplacés habituellement par « arg0 », « arg1 », …, « argn » à la compilation.
• @BindBean : l’annotation permet de faire le lien entre les attributs d’un objet et les paramètres de la requête.
L’utilisation des DAO est possible après l’avoir lié à un objet « Handle » :
|
1 2 3 4 5 |
// Utilisation du DAO Produit pour récupérer un produit par sa clef primaire Optional<Produit> soda = this.jdbi.withHandle(handle -> { ProduitDao produitDao = handle.attach(ProduitDao.class); return produitDao.get("1234567891011"); }); |
Externaliser les requêtes SQL
Que l’on utilise les méthodes de l’objet « Handle » ou les interfaces DAO, les requêtes SQL sont écrites directement dans le code.
Il est possible d’externaliser dans des fichiers de ressources toutes les requêtes SQL. Il est même envisageable de modifier les requêtes « à chaud » car JDBI embarque un système de cache invalidant les requêtes un certain temps après le dernier accès.
Pour récupérer simplement une requête grâce à ce mécanisme, on utilise la classe « ClasspathSqlLocator » :
|
1 2 3 4 |
//Récupération d’une requête depuis un dossier de ressource. String requete = ClasspathSqlLocator.findSqlOnClasspath("fr.osaxis.jdbi.modele.Produit.get"); /* Ou de manière similaire */ String requete = ClasspathSqlLocator.findSqlOnClasspath(Produit.class, "get"); |
La requête de l’exemple ci-dessus est récupérée du fichier « get.sql » se situant dans le dossier de ressources « fr/osaxis/jdbi/modele/Produit/ ». Ce dossier doit être accessible depuis le classpath de l’application.
Pour une utilisation avec les interfaces DAO, il suffit d’annoter l’interface avec @UseClasspathSqlLocator :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
@UseClasspathSqlLocator public interface ProduitDao { /* L’annotation n’a plus besoin de la définition de la requête SQL. */ @SqlQuery /* Elle est récupérée depuis le fichier de ressource * fr/osaxis/jdbi/dao/ProduitDao/get.sql */ @RegisterRowMapper(ProduitRowMapper.class) Optional<Produit> get(@Bind("ean13") String ean13); } |
Transactions
Les méthodes « useHandle » et « withHandle » n’ont pas de notion de transaction (hormis celles implicites, gérées par le SGBD).
Ces deux méthodes permettent simplement d’ouvrir une connexion à la base (ou d’en récupérer une depuis le pool de connsexions), et de l’utiliser et de la relâcher (fermeture ou remise à disponibilité du pool).
Pour les besoins transactionnels, l’objet « Handle » propose deux méthodes similaires à « useHandle » et « withHandle » qui sont « useTransaction » et « inTransaction ».
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
// Création d’une liste de courses contenant un nouveau produit, dans le cadre d’une transaction. String listeCoursId = UUID.randomUUID().toString(); this.jdbi.useTransaction(handle -> { handle.createUpdate("INSERT INTO liste_course (id, commentaire, etat) VALUES (?, ?, ?)") .bind(0, listeCoursId) .bind(1, "Attention, supermarché ferme à 19h30.") .bind(2, ListeCourseEtatEnum.OUVERTE.name()) .execute(); handle.createUpdate("INSERT INTO produit (ean13, nom, description) VALUES (:ean13, :nom, :description)") .bind("ean13", "1234567891011") .bind("nom", "Soda") .bind("description", "Soda rafraîchissant en bouteille") .execute(); handle.createUpdate("INSERT INTO liste_course_item (liste_course_id, produit_ean13, quantite) VALUES (:listeCourseId, :ean13, :quantite)") .bind("listeCourseId", listeCoursId) .bind("ean13", "1234567891011") .bind("quantite", BigDecimal.ONE) .execute(); }); |
Ainsi, une erreur lors de l’exécution du bloc annule la transaction et aucune donnée n’est insérée.
Dans le cas de l’utilisation des classes DAO gérées par l’extension SqlObject, une annotation est disponible pour indiquer que l’opération doit s’effectuer dans une transaction :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
// La méthode « insert » du DAO « Produit » doit s’exécuter dans un contexte transactionnel. public interface ProduitDao { /* ... */ @Transaction @SqlUpdate("INSERT INTO produit (ean13, nom, description) VALUES (:ean13, :nom, :description)") void insert(@Bind("ean13") String ean13, @Bind("nom") String nom, @Bind("description") String description); /* ... */ } |
Quelle que soit la méthode utilisée, il est possible d’indiquer le niveau d’isolation de la transaction. Il s’agit d’un paramètre supplémentaire aux méthodes « inTransaction » et « useTransaction » et de l’unique attribut de l’annotation @Transaction.
Autres fonctionnalités
JDBI possède d’autres fonctionnalités comme son intégration avec des librairies tierces. Sous forme de plugins, il faut déclarer leur utilisation lors de la création de l’instance JDBI :
|
1 2 |
// Déclaration de l’utilisation d’un plugin spécifique aux bases de données H2 this.jdbi.installPlugin(new H2DatabasePlugin()); |
Il existe des plugins spécifiques à quelques moteurs de bases de données (H2, Oracle, PostgreSQL par exemple) afin de profiter de fonctionnalités propres à ces SGBDs.
Autre exemple : un plugin Guava est disponible pour l’utilisation directe des collections et structures de données propre à cette librairie.
Le mot de la fin
JDBI est une librairie très complète qui permet de s’abstraire d’opérations fastidieuses par rapport à l’utilisation directe de l’interface JDBC.
Les différentes possibilités de récupération et transformation des données issues de requêtes pour en créer des objets Java en font une boîte à outils très pratique pour ceux qui ne souhaitent pas mettre en place une solution plus lourde comme un ORM.
Son API de bas niveau assure également un contrôle complet sur les paramètres JDBC ainsi qu’un contrôle fin des éléments du requêtage SQL.
Ressources
Site officiel JDBI et documentation : http://jdbi.org
Code source du projet JDBI : https://github.com/jdbi/jdbi
Il est possible de retrouver l’intégralité de cet article dans les numéros 227 et 228 du mois de mars et avril 2019 du magazine « Programmez ».